Introducción
En esta ocasión vamos a plantear una cosilla con la que llevo peleándome desde antes de navidades. Bien, hace unos meses estuvimos viendo cómo realizar una prueba de concepto de CQRS con Event Sourcing (de la que hablaré mas abajo). La idea me pareció interesante, por otro lado estuve viendo dos cursos: uno de Apache Kafka y otro de Mongo. Por que también me parecía interesante hacer algún proyectillo de prueba en el que estuviesen presentes estas tecnologías.
CQRS
La primera cuestión que el lector puede que se plantee es: qué demonios es esto de CQRS. Bien, CQRS por lo que se es un concepto conocido como Segregación de Responsabilidad de Consultas y Comandos. Este patrón fue introducido por Greg Young (Os sugiero que busquéis en Youtube conferencias suyas o leáis algún artículo es muy bueno).
Este patrón nos sugiere por un lado que hagámos una separación entre las consultas del dato de nuestro dominio, lo que se denomina Query y que son únicamente lecturas. Por otro lado lo que vienen siendo Agregados (escrituras, modificaciones y borrados) en lo que denominaremos Commnand.
¿Por qué hacer esta separación?. Pensémos en un dominio de dato que tenga un elevadísimo número de lecturas pero un reducido numero de modificaciones. También pensemos en que queremos tener un histórico de todas las modificaciones que se realizan en los datos. Además también deseamos tener una base de datos optimizada para escrituras y otra optimizada para lecturas (Por ejemplo un Cassandra para lecturas y un MySQL para escrituras,modificaciones y borrados). Aparte podríamos tener la posibilidad de poder ofrecer unos recursos (espacio, memoria, contenedores, cpu…) para las consultar y otro para los comandos. Más o menos esta es un poco la idea que se me quedó de este patrón.
Event Sourcing
Entonces resumiendo: quiero separar el servicio de consultas (Query) y el de comandos (Command). Y no solo eso, quiero además que tengan bases de datos distintas; puede que con el mismo dato o una versión reducida de éste. Pensemos, voy a poder hacer frente a un elevado número de consultas, y que las modificaciones,borrados e inserciones no bloqueen el servicio de consultas.
¿Pero cómo voy a hacer que las bases de datos estén iguales, consistentemente y con los mismos datos?. Si planteo que cuando se haga una modificación se realiza una petición (Por ejemplo REST) al servicio de consulta, estoy otra vez como al principio con el mismo problema. Es ahí donde entra el Event Sourcing, o flujo de eventos.
La idea es la siguiente: en lugar de que el servicio de comandos llame directamente y de forma síncrona al servicio de consulta para que actualice los cambios vamos a trabajar con un flujo de eventos. Puede ser implementado de muchas maneras, pero en que en nuestro caso tendrá la forma de un broker de mensajes con la tecnología de Apache Kafka.
Que ventajas nos proporciona este patrón, bien basándome en la escasa experiencia que tengo en el tema puedo nombrar dos.
-
Por un lado vamos a poder hacer frente a un mayor número de peticiones, al disponer de dos servicios podemos dar más recursos a las lecturas que a las escrituras y modificaciones. Además, en caso de haber muchísimas peticiones de lectura, hemos tener en cuenta que las modificaciones que se hagan mediante el broker de mensajes serán asíncronas, y no bloquearán las operaciones de lectura que se estén demandando en el micro-servicio de consulta en este caso.
-
La segunda cosa que nos proporciona este patrón es que dado que todos los comandos que se realicen van a ser mensajes del broker dispondremos de un histórico con todos los cambios que se han ido realizando en el modelo, dominio en el dato en cuestión.
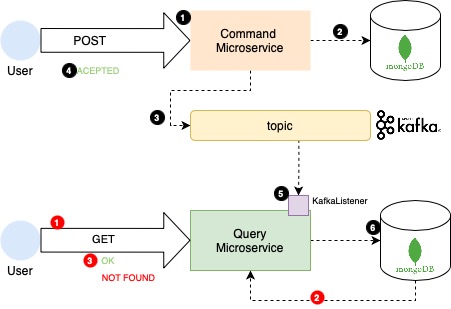
Resumiendo, vamos a a tener dos servicios separados con dos bases de datos separadas. El comando se va a encargar solo de aceptar peticiones para modificar, crear o eliminar. Y va a comunicarse de forma asíncrona con el servicio de consulta para que éste refleje estos cambios en su base de datos.
Esto nos plantea una situación un tanto inusual ya que cuando yo por ejemplo creo un nuevo registro, no tengo la garantía de que se cree en el momento, sino de forma asíncrona. Lo explico en el dibujo de más arriba en dos flujos.
Flujo command (negro)
- Realizo una petición al servicio para crear un nuevo Teléfono (Sí, en este caso hablámos de una base de datos de teléfonos).
- Se inserta un nuevo registro en la base de datos del micro-servicio de Command.
- En el topic del broker de mensajes se envía los datos del evento que ha ocurrido, hemos introducir un nuevo teléfono, y los datos necesarios para que el servicio de query inserte este teléfono en su base de datos.
- En lo que respecta al usuario, ya le podemos dar el resultado de la operación. Pero no podemos darle un
OK, ya que si el hace en el momento unGETal servicio de query verá que ese dato aún no existe, es necesario que la operación asíncrona se realice y se efectúen los cambios. No sabemos cuanto va a tardar esto, puede ser segundos o si el servicio de query esta a tope, minutos. Por lo tanto en lugar de decirle OK, le decimos ACCEPTED. Es decir, hemos oído tus peticiones estamos trabajando en ello. - En el servicio de consulta hay un Listener escuchando el topic de Kafka, cuando buenamente pueda recibiría el mensaje. He realizado una prueba de concepto con varios contenedores de Query, y un solo topic de kafka, y he podido comprobar que solo le llega a uno.
- Finalmente una vez el query ha obtenido el mensaje con el evento y
JSONinserta en la base de datos de Query los cambios realizados quedando ambas bases de datos iguales.
Flujo query (rojo)
De este no hay mucho que decir, se realizan únicamente operaciones de lectura de la base de datos. Y hay que tener en cuenta que puede darse el caso de que se realice una operación de agregación en el command y aún no se haya visto reflejada en el query por encontrarse el evento aun pendiente de procesar en el broker de Kafka.
Implementando la prueba
Para esta prueba de concepto vamos a plantear una hipotética aplicación de móviles, en la que dispondremos de la siguiente información:
{
"name": "iphone12",
"model": "11",
"color": "red",
"price": 800.99
}
docker-compose
Para esta prueba de concepto, vamos a dejar desplegados en docker contenedores para todo aquello que necesitamos:
- También dispondremos de un contenedor con Apache Kafka con un topic para gestionar los eventos. Y un Apache Zookeper en otro contenedor.
- Dos contenedores con Mongo, una para query y otro para command.
A continuación mostramos como hemos planteado el docker-compose:
version: '3'
services:
app:
build:
context: ./
dockerfile: Dockerfile
image: app
hostname: app
ports:
- "8081:8081"
depends_on:
- mongodb
networks:
- my-network
mongodb:
image: mongo:latest
container_name: "mongodb"
hostname: mongodb-host
environment:
- MONGO_INITDB_ROOT_USERNAME=mongoadmin
- MONGO_INITDB_ROOT_PASSWORD=secret
- MONGO_INITDB_DATABASE=example
ports:
- "27017:27017"
networks:
- my-network
volumes:
- ./data/init-mongo.js:/docker-entrypoint-initdb.d/mongo-init.js:ro
networks:
my-network:
driver: bridge
Spring Boot
Como ya hemos hecho en otros proyectos seguiremos una estructura hexagonal a la hora de definir los paquetes. Tenemos dos micro-servicios el command y el query. Cada uno con su correspondiente base de datos mongo. Y un broker de mensajes Kafka para comunicar eventos
Command
Esta aplicación dispone de de un único endpoint que lo que hará será primero escribir en la base de datos y seguidamente enviar el evento al broker de kafka.
@Service
@Log4j2
public class CreateUserService {
@Autowired
private PhoneConverter phoneConverter;
@Autowired
private PhoneRepository phoneRepository;
@Autowired
private KafkaPhoneCreatedEventSourcing kafkaPhoneCreatedEventSourcing;
@Transactional
public PhoneCreatedEvent create(CreatePhoneRequest request) {
log.info("Creating new phone");
val phone = phoneConverter.createPhoneRequestRequestToPhone(request);
phoneRepository.save(phone);
try {
return kafkaPhoneCreatedEventSourcing.publicCreatePhoneEvent(phone);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
}
Aquí podemos ver básicamente el flujo que se sigue. En caso de producirse algún error al publicar el mensaje en el broker se deshacen los cambios realizados en la base de datos.
A continuación explicamos como vamos a realizar para enviar los mensajes al broker de kafka:
public PhoneCreatedEvent publicCreatePhoneEvent(Phone phone) throws JsonProcessingException {
val id = UUID.randomUUID();
ObjectWriter objectWriter = new ObjectMapper().writer().withDefaultPrettyPrinter();
val json = objectWriter.writeValueAsString(phone);
log.info("Send json '{}' to topic {}", json, topicName);
kafkaTemplate.send(topicName, json);
return PhoneCreatedEvent.builder().uuid(id).phone(phone).build();
}
Como podemos ver se le asigna a cada evento un id, se le envía la información necesaria para que en Query se reflejen los cambios y se envia al kafka. Con esto ya habríamos finalizado en este servicio y devolveríamos a quien nos ha llamado un ACCEPTED indicando que su petición ha sido aceptada.
Query
No vamos a entrar en detalles de que hay detrás del GET que únicamente consulta en la base de datos de Query si está presente el id que nos indican y devuelve en su lugar. Lo que si quiero mostrar aquí es el Listener que estará escuchando el broker de kafka en espera de un mensaje de evento:
@Log4j2
@Component
public class KafkaCreatePhoneEventListener {
@Autowired
private FindPhoneService findPhoneService;
private final CountDownLatch latch = new CountDownLatch(3);
@KafkaListener(topics = "${message.topic.createPhone}")
public void listen(ConsumerRecord<String, String> stringStringConsumerRecord) throws Exception {
Phone phone = new Gson().fromJson(stringStringConsumerRecord.value(), Phone.class);
findPhoneService.createPhone(phone);
log.info("Insert phone {} in reader database", phone);
latch.countDown();
}
}
Como podemos observar este KafkaListener esta a la espera de que llegue un mensaje por parte del broker. Como indiqué más arriba en caso de existir múltiples servicios levantados, solo le llegará a uno de ellos por defecto lo cual nos viene genial. Una vez recibido el objeto que llegará en forma de JSON se transforma a un objeto de tipo Phone y seguidamente se inserta en la base de datos.
La prueba
Bien una vez están levantados todos los contenedores de docker (los dos mongos, el broker de apache kafka y el zookeeper), y los dos micro-servicios el command y query. Procedemos a probar el flujo que hemos dibujas o en el diagrama superior:
- En primer lugar vamos a realizar POST para insertar un nuevo terminal.
curl --location --request POST 'localhost:8081/phone' \
--header 'Content-Type: application/json' \
--data-raw '{
"name": "iphone8",
"model": "11",
"color": "red",
"price": 800.99
}'
Si observamos el log tanto de un micro-servicio query como de command, podremos observar como se va realizando el flujo.
A continuación vamos a comprobar que el teléfono se ha dado de alta en la base de datos de query:
curl --location --request GET 'localhost:8082/phone/iphone12'
Además, podemos comprobar mediante un cliente MONGO que ambas base de datos incluyen este nuevo registro.
Conclusión y cosas a tener en cuenta
Bueno por lo que vemos funcionar funciona. pero es todo un poco enrevesado. He estado viendo que existen soluciones muy elegantes y que hacen el código más limpia. Una de ellas es utilizar Axon.
Axon
¿Qué es Axon? como bien nos indican en su web:
Axon provides a unified, productive way of developing Java applications that can evolve without significant refactoring from a monolith to Event-Driven microservices. Axon includes both a programming model as well as specialized infrastructure to provide enterprise ready operational support for the programming model - especially for scaling and distributing mission critical business applications. The programming model is provided by the popular Axon Framework while Axon Server is the infrastructure part of Axon, all open sourced. If you want to scale-up, go for Axon Server Enterprise and reach out for details about pricing and possibilities.
Web de Axon
Tengo previsto hablar mucho mas de Axon, y realizar esta misma prueba de concepto con Axon una vez finalice un curso de Udemy que estoy realizando sobre ello; pero en resumidas cuenta los que nos proporciona Axon es un servidor con una base de datos encargado de orquestar y gestionar todo lo referente a eventsourcing y en los command y queries, unas anotaciones para gestionar tanto el envio de eventos como los listener que reaccionan a estos. Asi explicado de forma rápida y con mis palabras.
Cosillas que me inquietan
Hablé con un compañero que domina bastante Kafka, y también estuve viendo varios videos y articulos sobre CQRS y en todos comentan que uno de los riesgos de utilizar un broker de mensajes es que en caso de fallo, el mensaje se va enviar si o si, pero podría producirse la situación de que por un error los mensajes se enviasen en orden incorrecto repetidos por algún problema de sincronizacion entre el zookeeper y el kafka, o una sobrecarca o caida de algun broker del cluster. ¿Que consecuencias podría tener esto? Pues las que mas temo, incosistencia de datos entre la base de datos de Command y la de Query.
Por lo tanto hay que tener en cuenta que hay que tener muy bien montado el tema del broker de mensajes y el zookeeper para evitar en todo lo posible este tipo de situacions.